cat blog/ai-agents-fantasy-football.mdx
I built a team of AI agents to do my fantasy-football homework
Every morning a team of AI agents logs into my Comunio World Cup league, reads the real football news, fact-checks itself and leaves me one dashboard — plus a growing intelligence file on the rivals I'm bidding against.
Jun 10, 2026 · #ai #agents #football
I’m in a fantasy league for the 2026 World Cup. Played properly, it’s a part-time job: every day there’s injury news to chase across a dozen sites, player prices moving, bids to weigh, and the nagging sense you’ve missed the one thing that matters. I didn’t want to spend my evenings doing that by hand.
So I did the obvious 2026 thing and got AI to do the homework for me.
Here’s the part I want to be precise about, because it’s the whole point. I did not write a program that scrapes the site on a timer and runs a few rules I typed in last month. I built a small team of AI agents. Every morning they log into the game, decide what’s worth looking up, go read the real-world football news, reason about what it means for my squad, fact-check their own conclusions, and leave me a single dashboard. The analysis is done fresh, on demand — not baked into code I wrote in advance. Hold onto that difference; it’s the line between a static tool and something closer to a colleague, and it’s the reason any of this matters to a business.
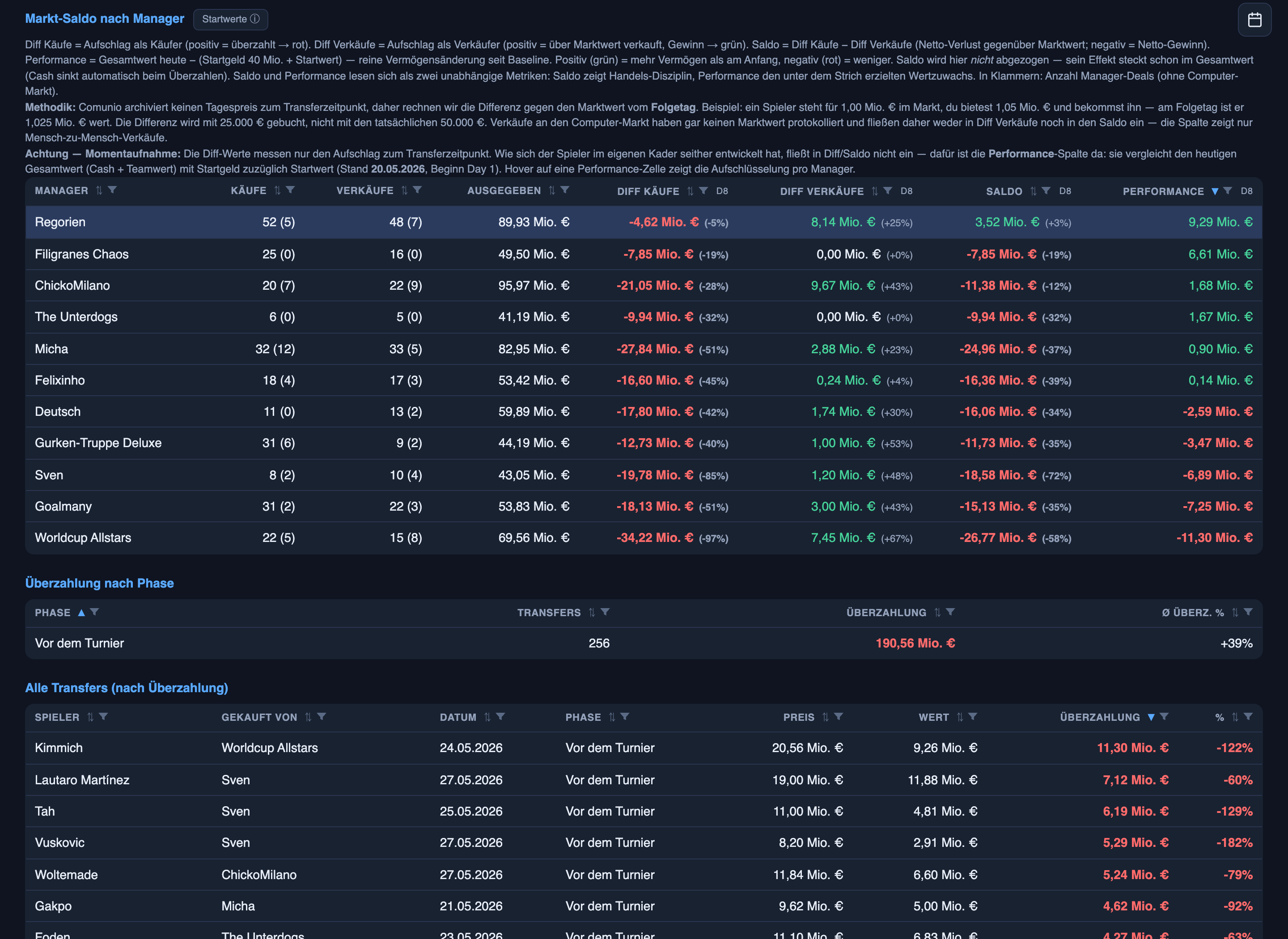
I built it to save myself time and to make better bids. Here’s the table I’d hand you if you asked me whether it works. Snapshot from this morning, the day before the opener:
| Manager | Buys | Net trading P&L | Wealth change since Day 1 |
|---|---|---|---|
| Worldcup Allstars | 22 | −26.77M | −11.30M (−20.6%) |
| Me | 52 | +3.52M | +9.29M (+17.3%) |
Same league, same players on the market, three weeks of trading. Worldcup Allstars’ total wealth has shrunk by a fifth. Mine has grown by a sixth. The gap between us at the bottom line is almost 21 million euros, and the World Cup hasn’t even kicked off.
That last column is the one I’d defend in a meeting. It isn’t a vibes metric: it’s the system’s own bookkeeping, comparing today’s cash + squad value against what each manager started Day 1 with. The middle column is the trading P&L that drives it — across every buy and sale combined, did you give value away or extract it? Worldcup Allstars went heavy on big names and lost 27M to overpay. I overpaid too — by single-digit percentages, because I do want certain players — but I also sold above market often enough to net positive on trading alone. Compounded over three weeks, you get a 21M gap from near-identical starting positions. (Near-identical, to be precise, in their favour: they began Day 1 slightly richer than I did.) The ledger itself is below, exactly as the dashboard renders it.
Now here’s why that table is worth more than it looks — and where it quietly stopped being about football for me.
In this game you don’t buy players off a visible price tag. You bid in a blind auction: everyone submits a sealed offer, nobody sees anyone else’s, and the highest number simply wins — like sealed-envelope bids on a contract. So the real question is never “what is this player worth?” It’s “what will the other managers throw at him?” And people are gloriously predictable about it: they overpay for big names (everyone wants the Messi, the Kimmich), and they lose their discipline at very specific moments.
Which is exactly what my agents have been quietly recording. Every purchase in the league, tagged with how far over fair value it went — by whom, on which player, on which day. Out of that falls a model of my opponents’ behaviour: who overpays, for which kind of player, when, and by how much. So when I place a sealed bid I’m not guessing into the dark — I’m pricing against what these specific rivals have always done. I let the undisciplined ones overpay for the shiny names and stay out of the war; and when I actually want someone, I bid just enough to clear their predicted number and not a euro more.
That’s the edge I built this for. In a market where I can’t see anyone’s bids until after they’ve won, the agents give me the next-best thing — a daily, growing intelligence file on the people I’m bidding against, so I can predict their behaviour before I commit. And it only works because the agents come back every morning and look again, rather than running a static analyser I wrote once and walked away from.
Let me back up and show you the whole thing.
What this actually is
The fantasy football game I’m playing is called Comunio. If you’ve never touched it: you manage a squad of real footballers on a real-money-style budget. Their values rise and fall with how they actually play out there on the grass, and you buy and sell them — in those blind auctions — against other human managers in your league. It’s the stock market, except the assets have hamstrings and you can’t see anyone else’s orders.
For the 2026 World Cup I’m in a league. And somewhere in the planning I had the thought every busy person eventually has: this is going to eat my evenings. So instead of doing the homework by hand, I built agents to do it — so I make the call in two minutes instead of two hours.
Every day, on their own, they:
- log into comunio.com and pull the live state of the league — my cash, my squad, the standings, who’s bidding on what
- go and read the real football news that moves player values
- fact-check their own conclusions against independent sources before trusting them
- produce score predictions for every match of the upcoming round, with confidence levels
- and render one dashboard: the money, the recommendations, the predictions, and the evidence behind every call
That’s it. One screen. I open it with my coffee, I see everything, I decide. Yes, I taught a pack of AI agents to do my homework, and no, I’m not sorry.
Here’s the tour. Watch what each part is really doing — and if you skim, skim the very last section, where I get into how it’s wired. The business is in 1 through 7.
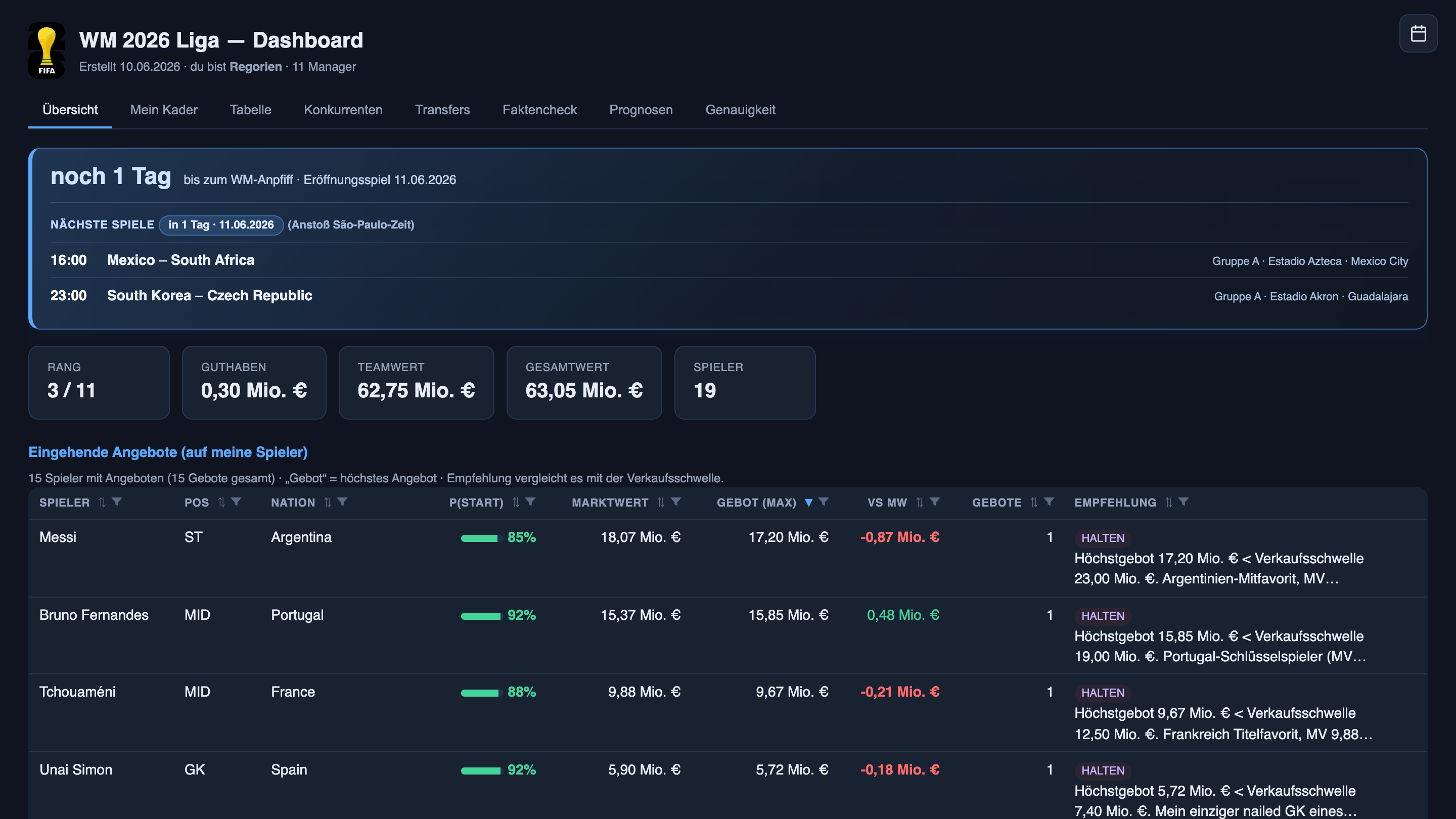
1. The money, at a glance
The top of the dashboard is five cards, refreshed this morning. Cash on hand: 0.30M — almost nothing, deliberately: I’m fully invested into the squad, and the strategy box says so in as many words (“squad complete, no mandatory buys — hold the cash for targeted upgrades”). Squad value: 62.75M. Total worth: 63.05M. Nineteen players. League rank: 3 of 11 by total worth.
That last number is worth pausing on. Comunio deals every manager a random starting squad, and it dealt me a weak one: my Day-1 squad was worth 13.76M, near the bottom of the league, while the best-stocked rival started at 20.70M — roughly 50% more than me. That’s the hand you get; complaining doesn’t move the table. Three weeks of disciplined trading later, the day before the World Cup actually starts, my portfolio sits near the top. The other managers can see the same rankings I can; they cannot see why mine has moved up.
2. The news comes to me — and it’s cited
This is where it stops being a toy.
Scattered through the squad view are little note cells, each with clickable source links. Here’s one story they tracked across a single week — my most expensive player:
Messi, a few days ago: new thigh/hamstring injury from the last MLS game. Training separately, misses both friendlies. Start-probability lowered to 50 — start not secured. (espn.com, rotowire.com)
Messi, this morning: upgraded back to fit — 20 minutes and a penalty goal in the Iceland friendly on 9 June; ESPN’s injury tracker has him “IN — Expected to Play”. Start-probability back up to 85. (espn.com, rotowire.com)
I didn’t chase any of that. The agents did, while I slept — first the bad news, then the recovery, each step with the receipts attached: ESPN, RotoWire, Sky Sports, CBS, Sports Mole, World Soccer Talk. Every claim links back to where it came from. Here’s what that looks like on the board — the squad view first, then what happens when you hover Messi’s row:
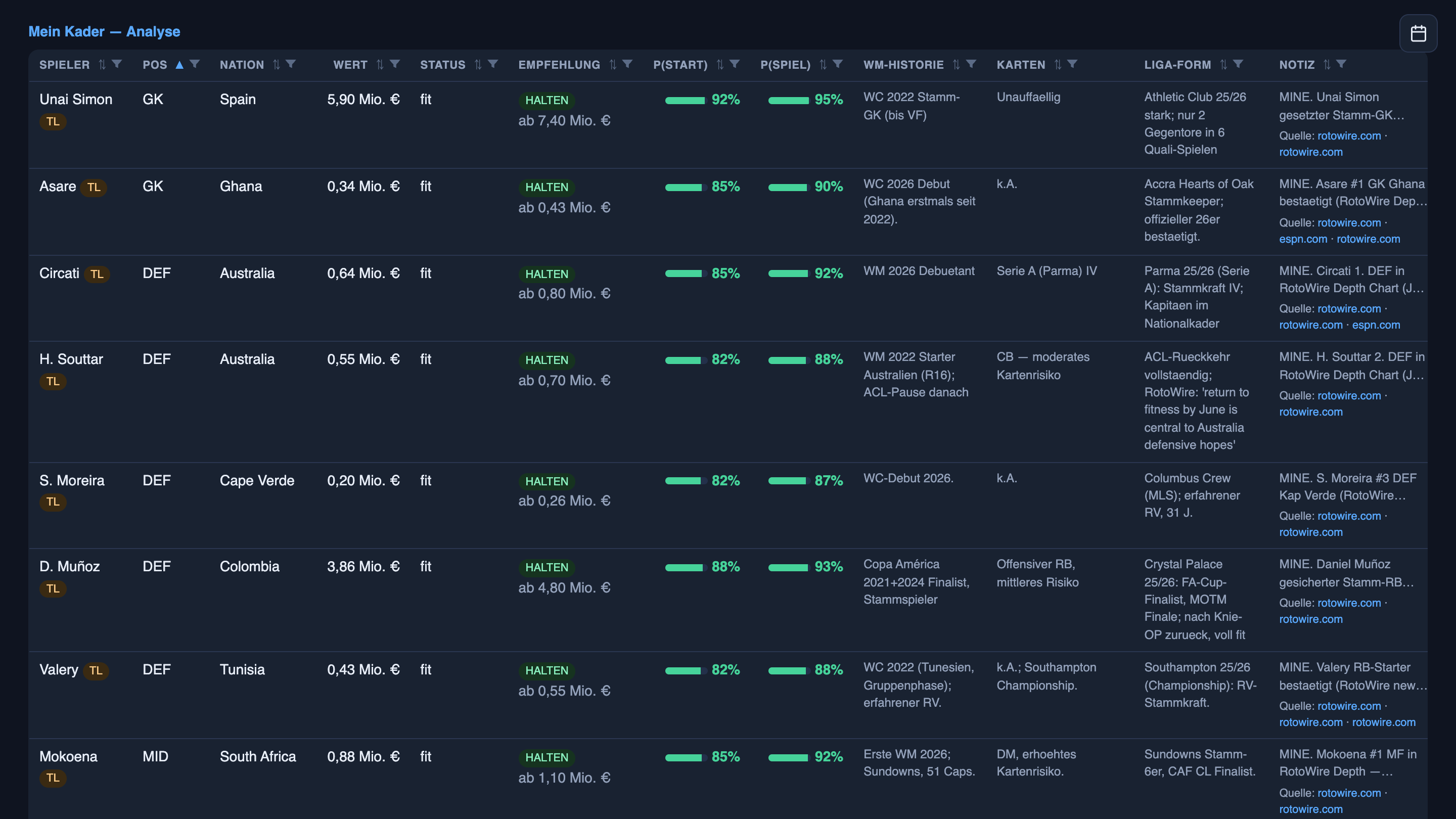
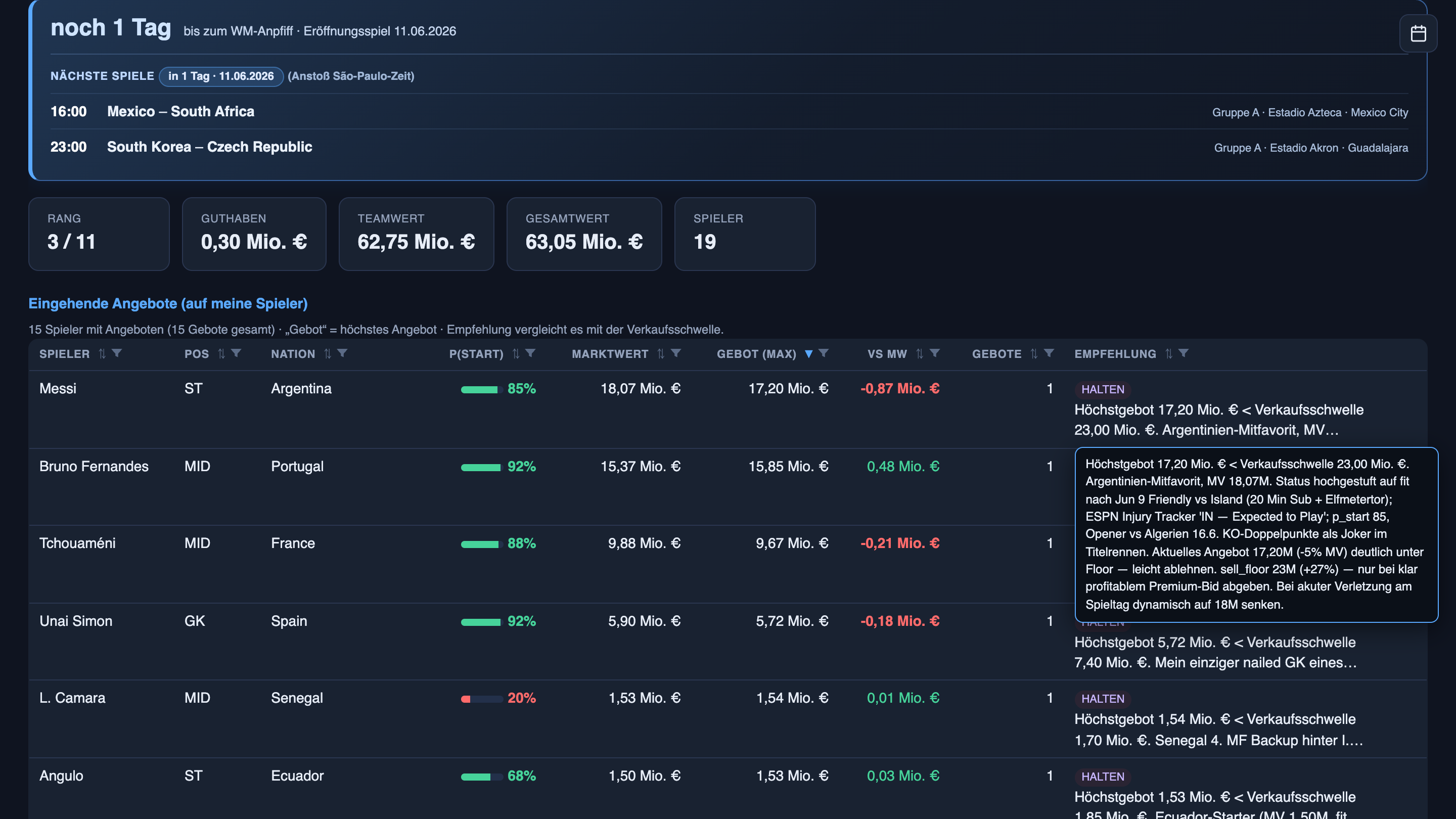
A claim with no source is a rumor. A claim with a link is something you can act on. The whole machine is built on that one distinction.
3. Recommendations — with a confidence number and a reason
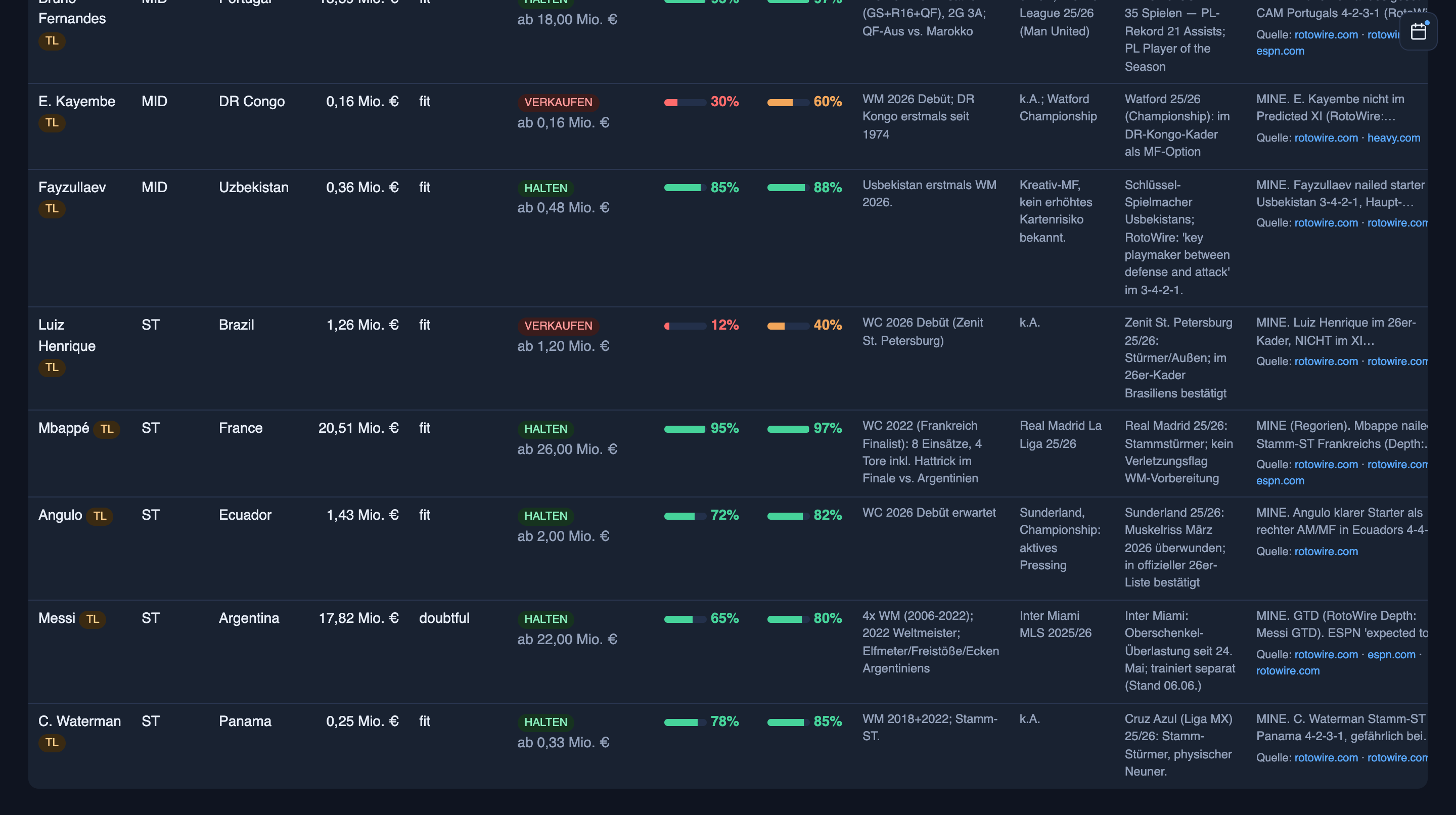
Every player gets a probability-of-starting bar and a tag: BUY, CHECK, HOLD, SELL, GAMBLE, or AVOID. Not vibes. A number and a verdict.
A few real ones, all from this morning’s board:
- Rogers — 62% to start — CHECK. England midfielder, on the market at 4.55M. This morning’s research had him at 50 — a coin flip. The audit pass went looking for something to settle it and came back with three independent signals: the betting market prices him 2/7 to start, the coach has half-named him, the depth chart agrees. Probability raised to 62, target price raised to 6.0M — and the verdict still stays CHECK, not BUY, “no official XI confirmation yet.” It even names the two cash-rich rivals likely to bid against me, with a note that both historically overpay.
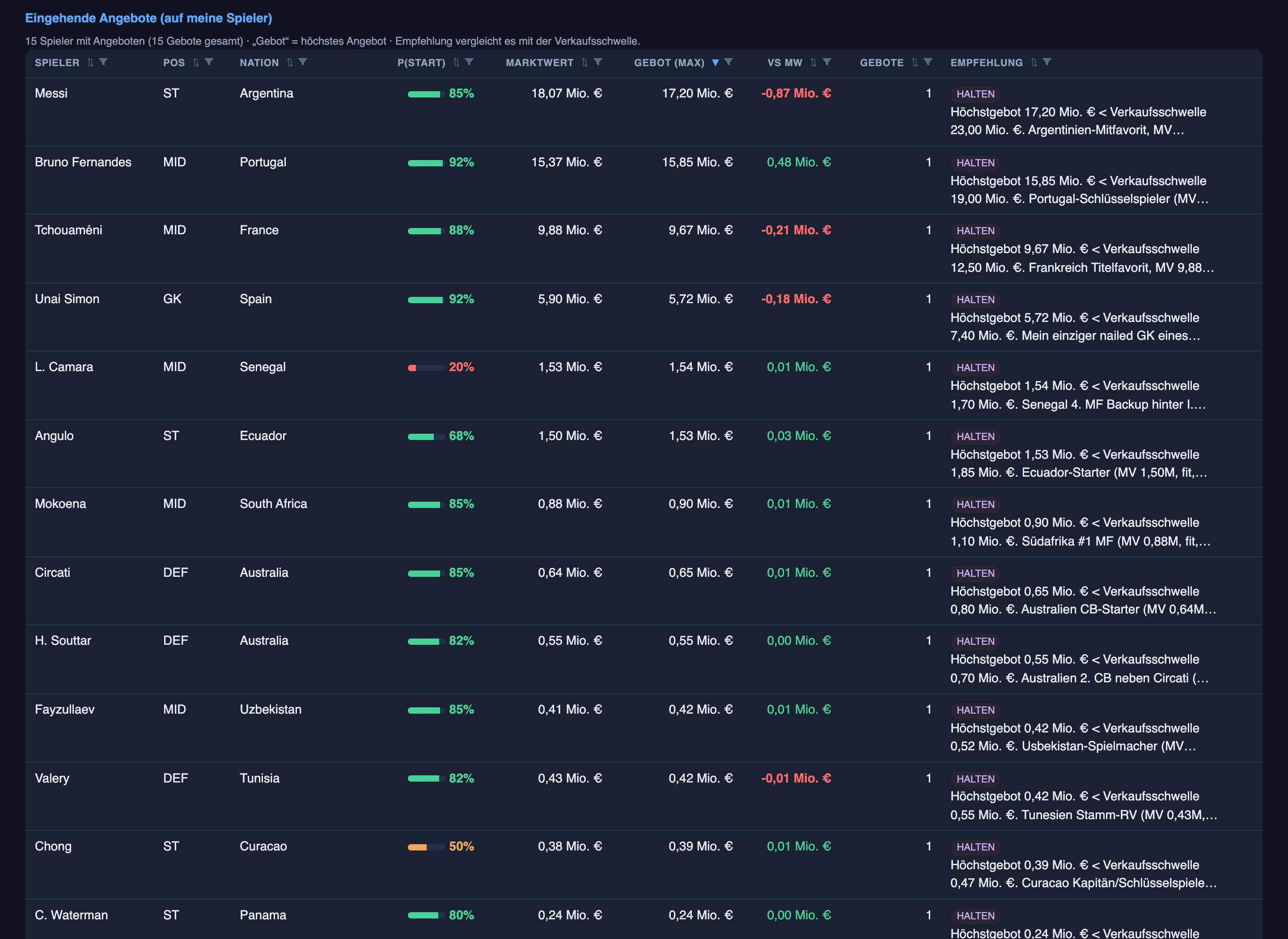
- Unai Simón — 92% — HOLD. “My only nailed-on goalkeeper of a title favourite. Spain’s first choice, no competition. The offer on the desk is 3% below market — decline. Don’t sell under 7.4M (+25%).”
- Nübel — 3% — AVOID. Germany’s third-choice goalkeeper, not even on the depth chart. “No bid makes sense.” Two rival managers — both currently without a keeper — are bidding on him anyway.
All three are sitting on today’s board. Rogers tops the transfer-target list, the Unai Simón offer is in the incoming-offers table, and the long-form reasoning lives in the squad recommendations:
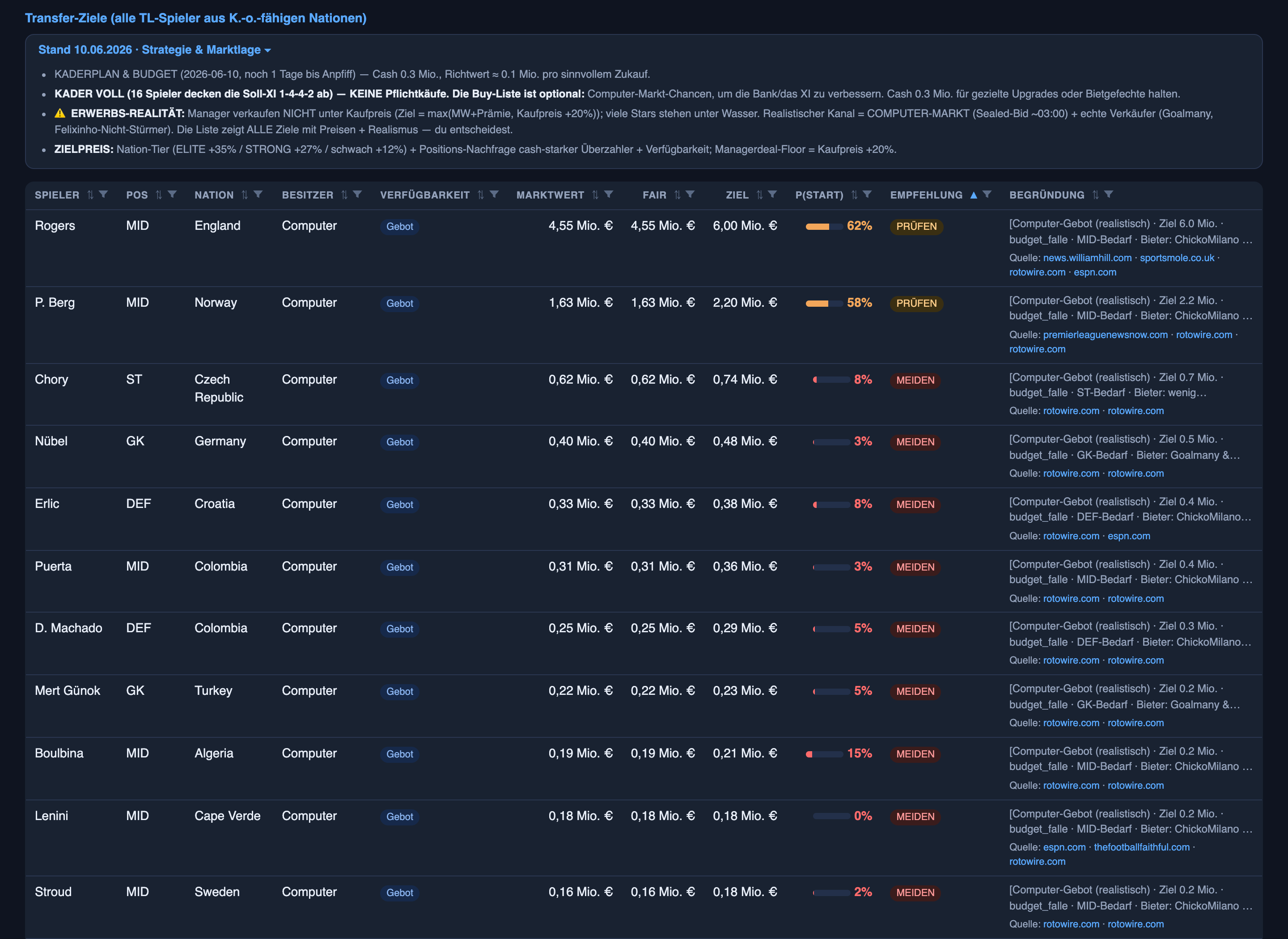

Look at the Rogers one again. The system didn’t leave a coin flip standing — it hunted down evidence, including a betting market, the one source with actual money riding on being right. Then it moved its own number, documented why, and still refused to upgrade the verdict past CHECK, because a probable starter is not a confirmed one. That’s not a machine pretending to be certain. That’s a machine showing its homework when it changes its mind — which is the only kind I’d trust with a decision. A machine that tells you when it’s unsure is worth ten that are always confident.
The target prices aren’t guesses either. There’s a model underneath: a premium for how strong the player’s nation is (an elite team adds +35%, a strong one +27%, a weaker one +12%), how scarce the position is, which cash-rich rivals are likely to bid against me — and whether the player is even available. Goals are weighted by position. Knockout rounds count double, because they do. It’s a valuation model that happens to be about footballers.
A short detour — read the last three sections back
Stop for a second and reread sections 1, 2 and 3 — but strip the football out.
A live view of your cash and your asset position, and the gap between what you nominally hold and what you can actually move today. A stream of outside news about the things you own, each item carrying a link to where it came from, gathered overnight without anyone lifting a finger. A set of ranked recommendations, each with a confidence level and a plain-English reason, that quietly downgrades itself when the evidence gets shaky — and that prices your move against rivals you can’t see.
That’s not a fantasy football screen anymore. That’s watching a portfolio, or monitoring a market, or pricing a sealed bid against competitors and suppliers whose hand you can’t see. Same pattern, different nouns. Which is the whole reason I’m writing this down.
Okay. Back to the game.
4. One cockpit instead of ten tabs
Everything lives on a single dashboard. A World Cup countdown banner across the top (“1 day to kickoff — opener 11.06.2026” — that’s tomorrow, and yes, that bit gives me a little thrill). Then the five money cards. Then incoming offers on my players. Then transfer targets with a collapsible strategy box. Then my squad and its recommendations.
Eight tabs — Overview, My Squad, Table, Competitors, Transfers, Fact-check, Predictions, Accuracy — and a floating date-picker that jumps between daily snapshots. I can time-travel through the league’s history and watch how a player’s story changed day by day. (The last two tabs are new this week. They’re the system grading itself — section 7.)
One of those tabs, the league table, is below — and it’s a good example of quiet intel, because Comunio’s own table shows the other managers exactly one column: squad value. Mine reconstructs the rest from the transfer ledger it’s been keeping — each manager’s cash, total worth, and a number I’m quietly proud of: buying power = cash plus a quarter of squad value, the Comunio rule for the most a manager can have tied up in open bids at once. That column tells me, for every rival, how much they can actually throw at a player right now. In a blind auction, knowing the ceiling of the bidding war you’re about to enter is the difference between guessing and pricing.
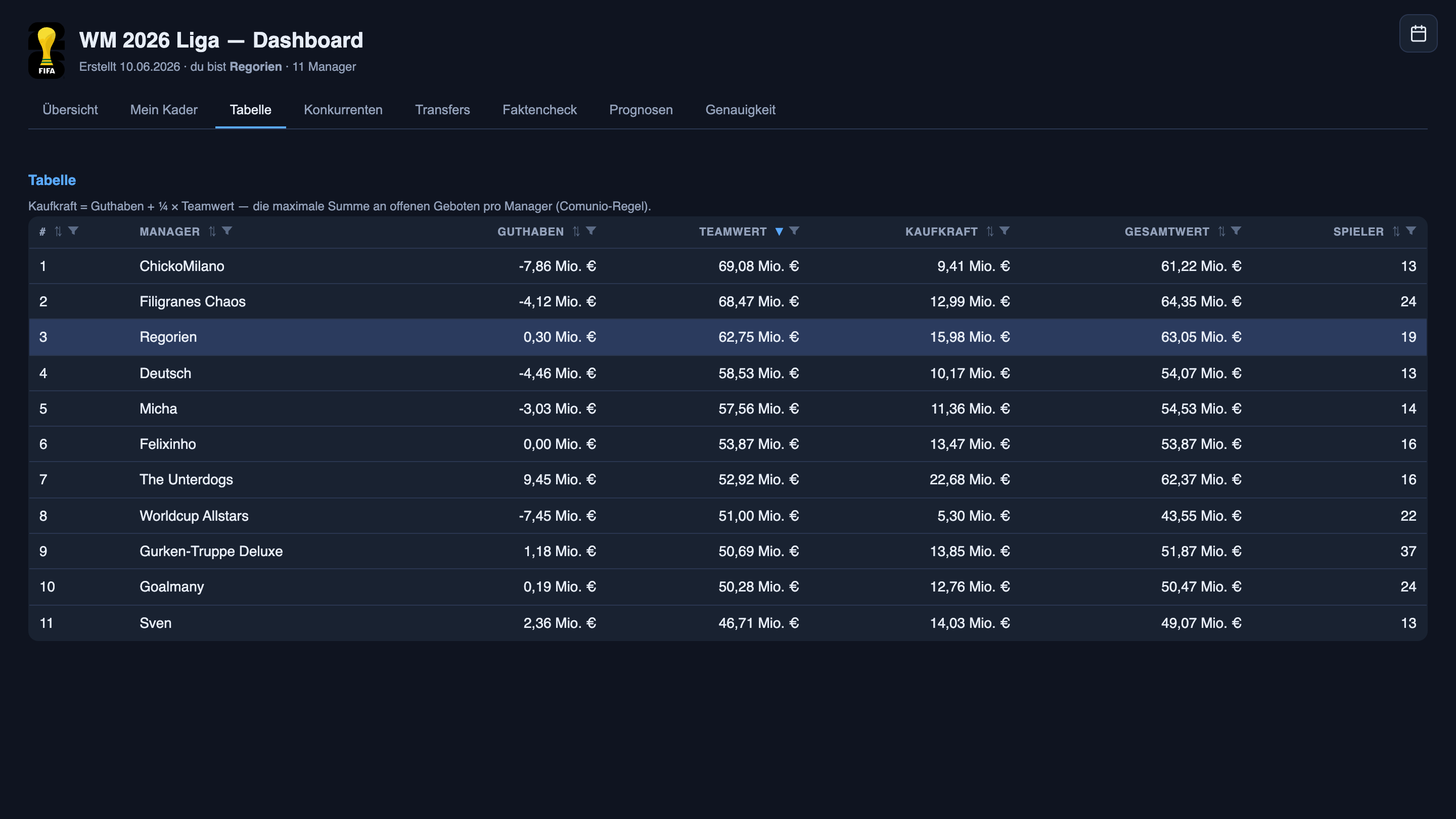
The point is that I’m not hunting anymore. Ten tabs and a spreadsheet got replaced by one screen that already did the hunting for me. Think of the report your team actually needs versus the one they spend Thursday afternoon assembling by hand. That’s the gap this closes.
5. The ledger — predicting who overpays, by how much, and when
Back to where we started, because in a blind-bid market this is the closest thing to seeing your opponents’ cards.
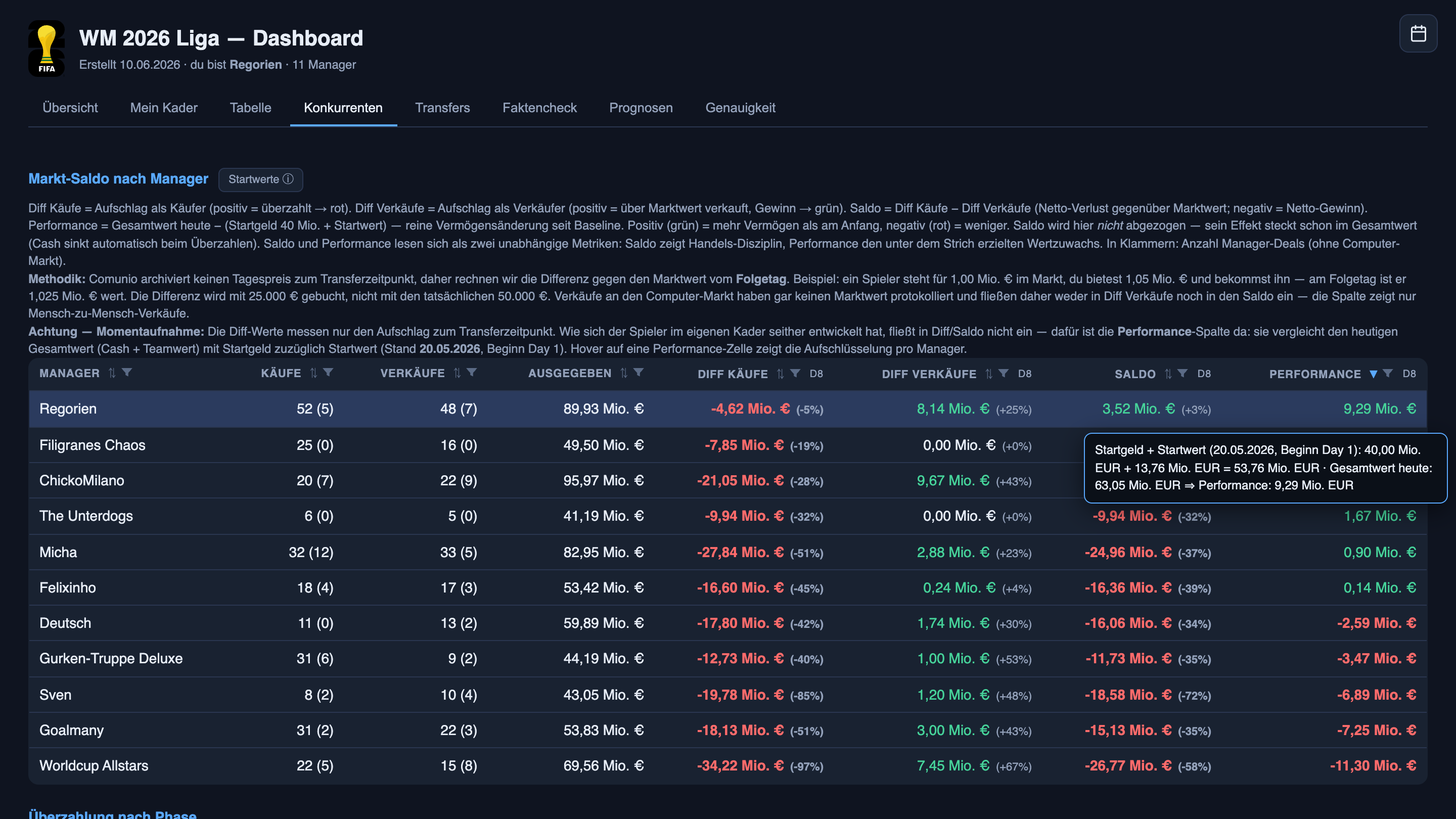
The system keeps a complete history of every purchase and sale in the league. For each manager it tracks four things: overpay as a buyer (money lost paying above market), premium as a seller (money extracted by selling above market), the net of those two, and the bottom line — how each manager’s total wealth has moved since Day 1.
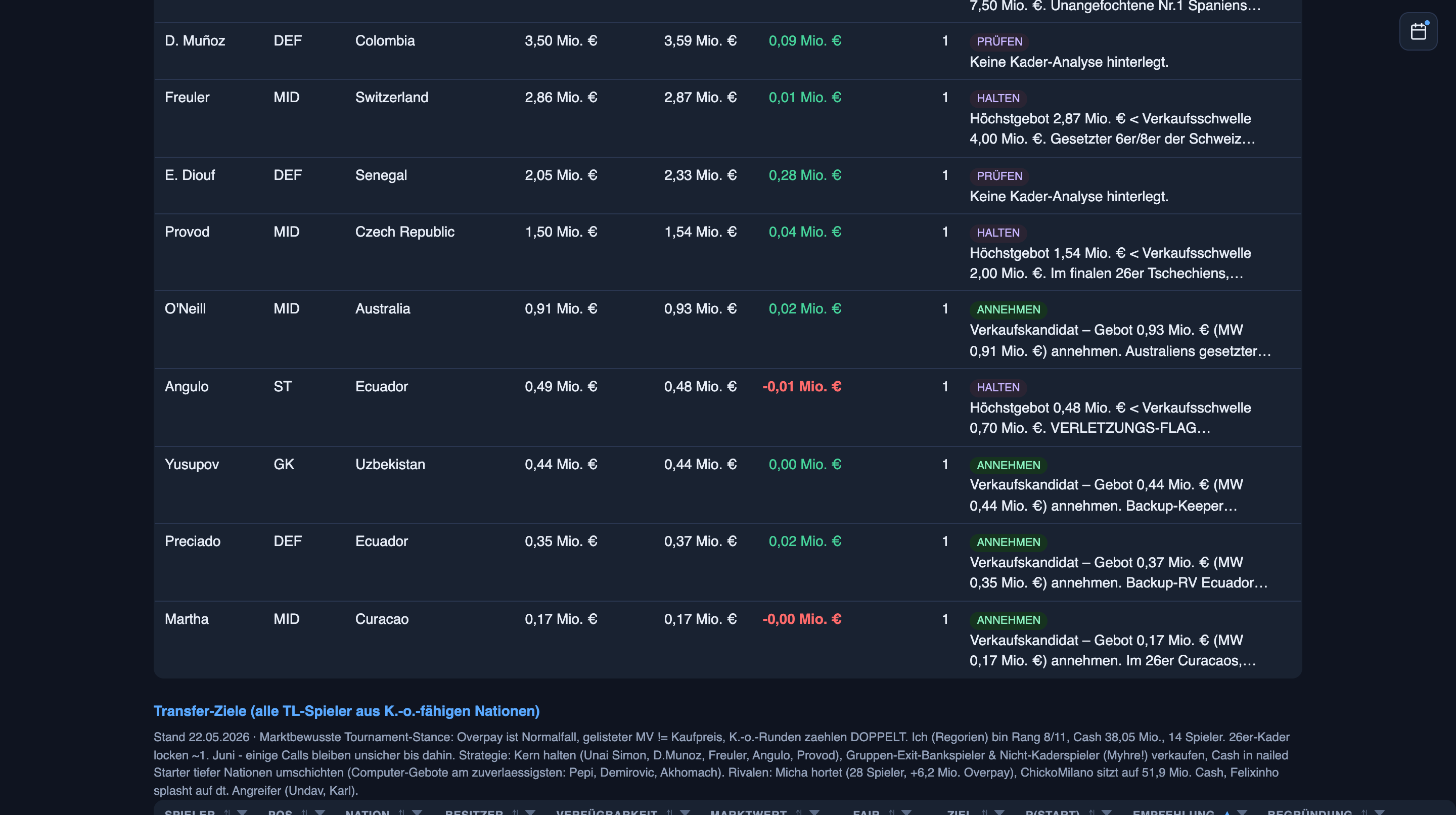
Worldcup Allstars, the opening table’s losing side, overpaid by +97% on average as a buyer (−34M lost to bidding wars), recovered some by selling at +67% (+7.4M extracted from someone else’s bidding war), but the net is −27M down. Total wealth: −20.6%. I overpaid too — by 5% on average, because I do want certain players — but when I sold, I averaged a +25% premium, enough to net positive on trading alone. Net: +3.5M trading P&L. Total wealth: +17.3%.
And because a metric you can’t decompose is a metric you shouldn’t trust, the two columns that matter explain themselves on hover:
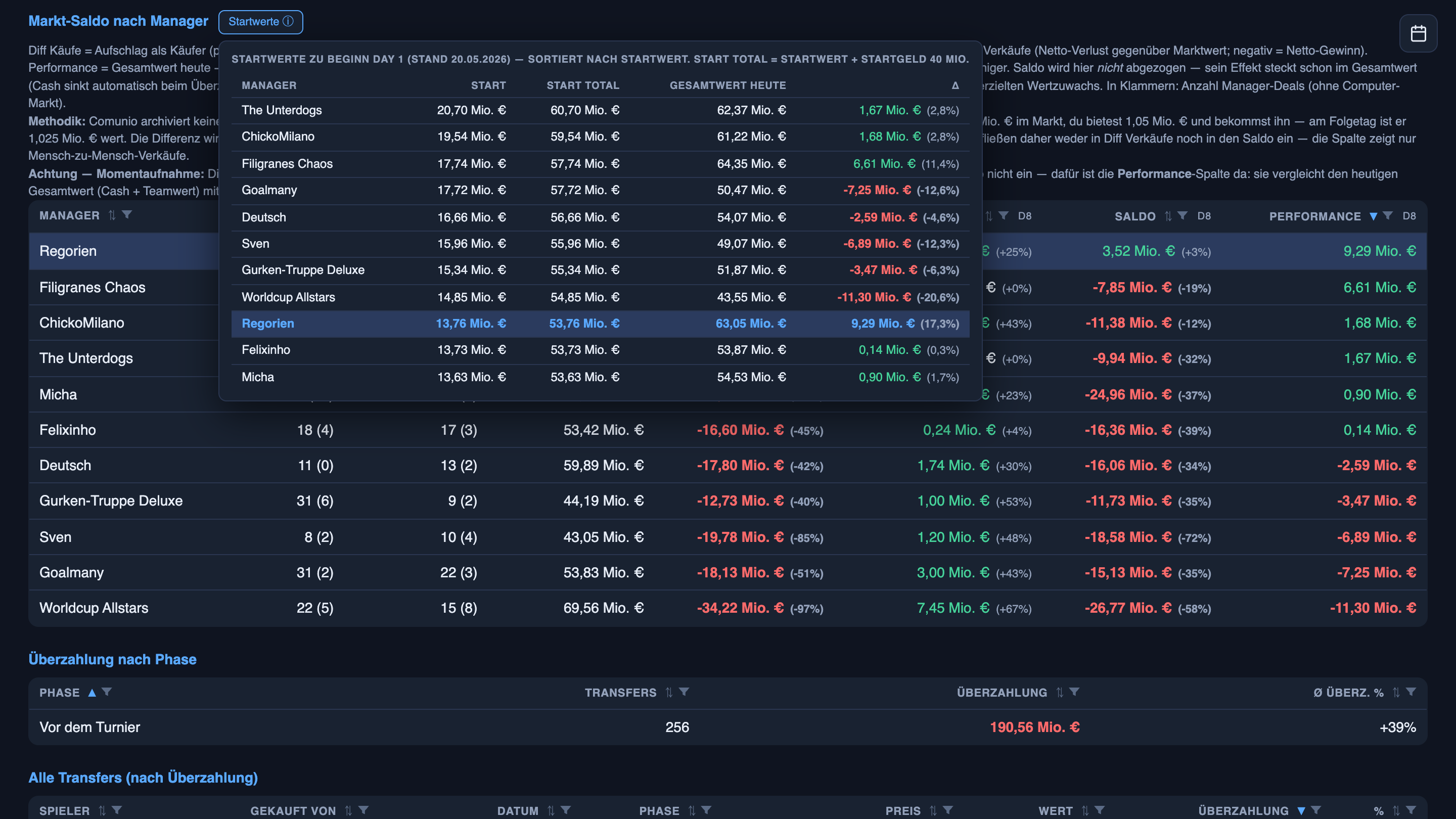
By phase of the tournament, the whole league has gone a little mad: in the pre-tournament window there have been 256 transfers, 190.56M in total overpay, an average +39% over fair value. And the per-player view turns up lines like this:
Kimmich, bought 24 May, paid 20.56M — market value the next day: 9.26M. Overpaid by 11.30M. +122%.
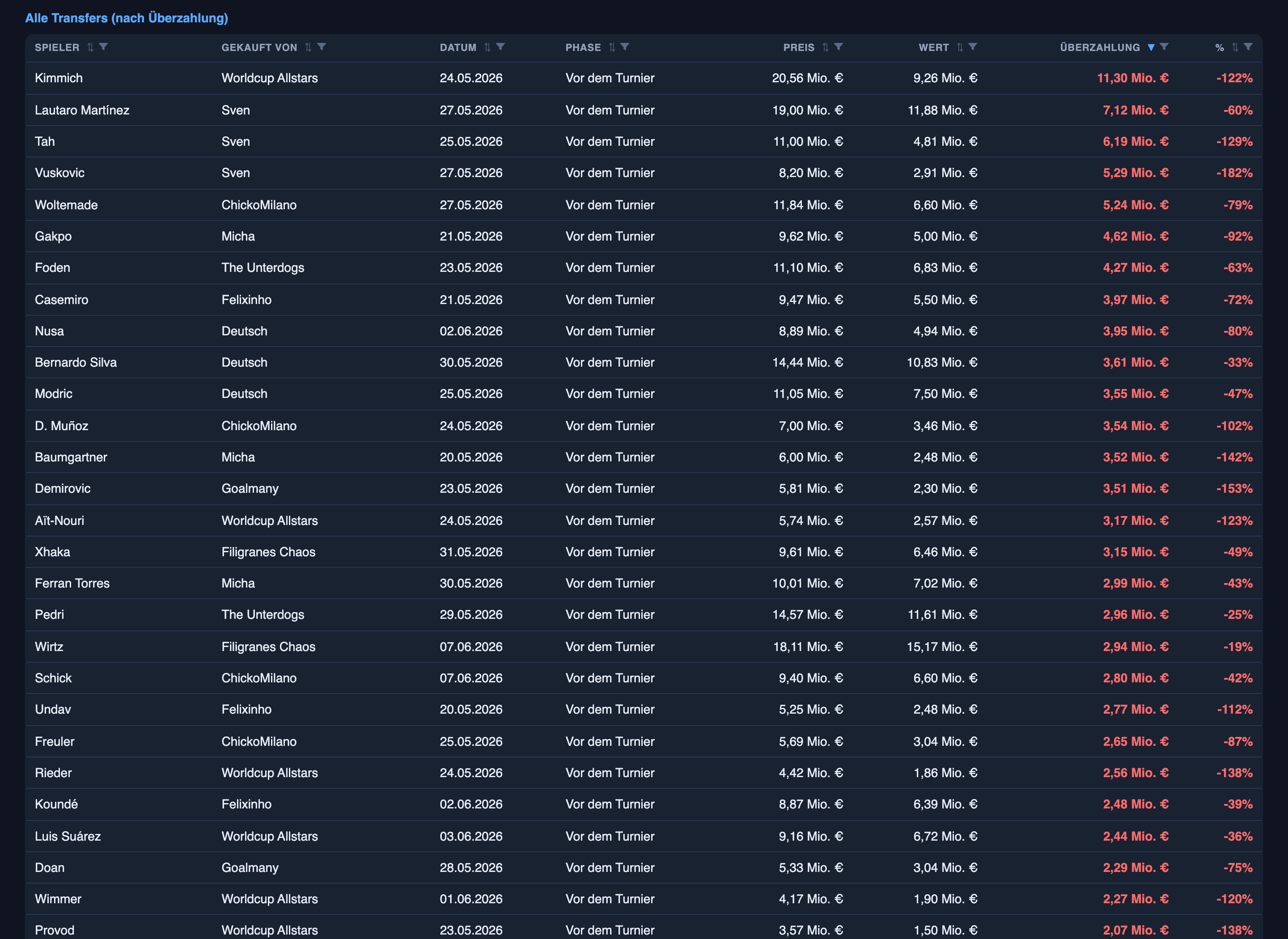
One man, more than double. And because the agents log every one of these, the pattern becomes a forecast: this manager always chases big German names, that one loses discipline the week before kickoff, this position reliably goes for +50%. In a sealed auction, that’s the edge — I’m no longer bidding against a player’s value, I’m bidding against a rival’s known habit.
I’ll do the noun-swap once, properly, so you can see the shape of it outside the game. I pointed the same idea — the same ledger, the same two-source rule — at a small set of supplier invoices for a friend who runs operations at a mid-sized firm. It flagged one vendor whose unit prices had crept up over several quarters while the market hadn’t moved, and it pinned the month the drift started. Nobody had noticed, because nobody was watching a single screen for it; the increases were small and spread across statements. That’s all it is. A ledger that never blinks, watching for the moment someone starts paying — or charging — too much, and learning each player’s pattern so the next move is predictable.
6. The part I’m most proud of: it fact-checks itself
Here’s what separates a real system from a clever demo. These agents don’t trust their own conclusions.
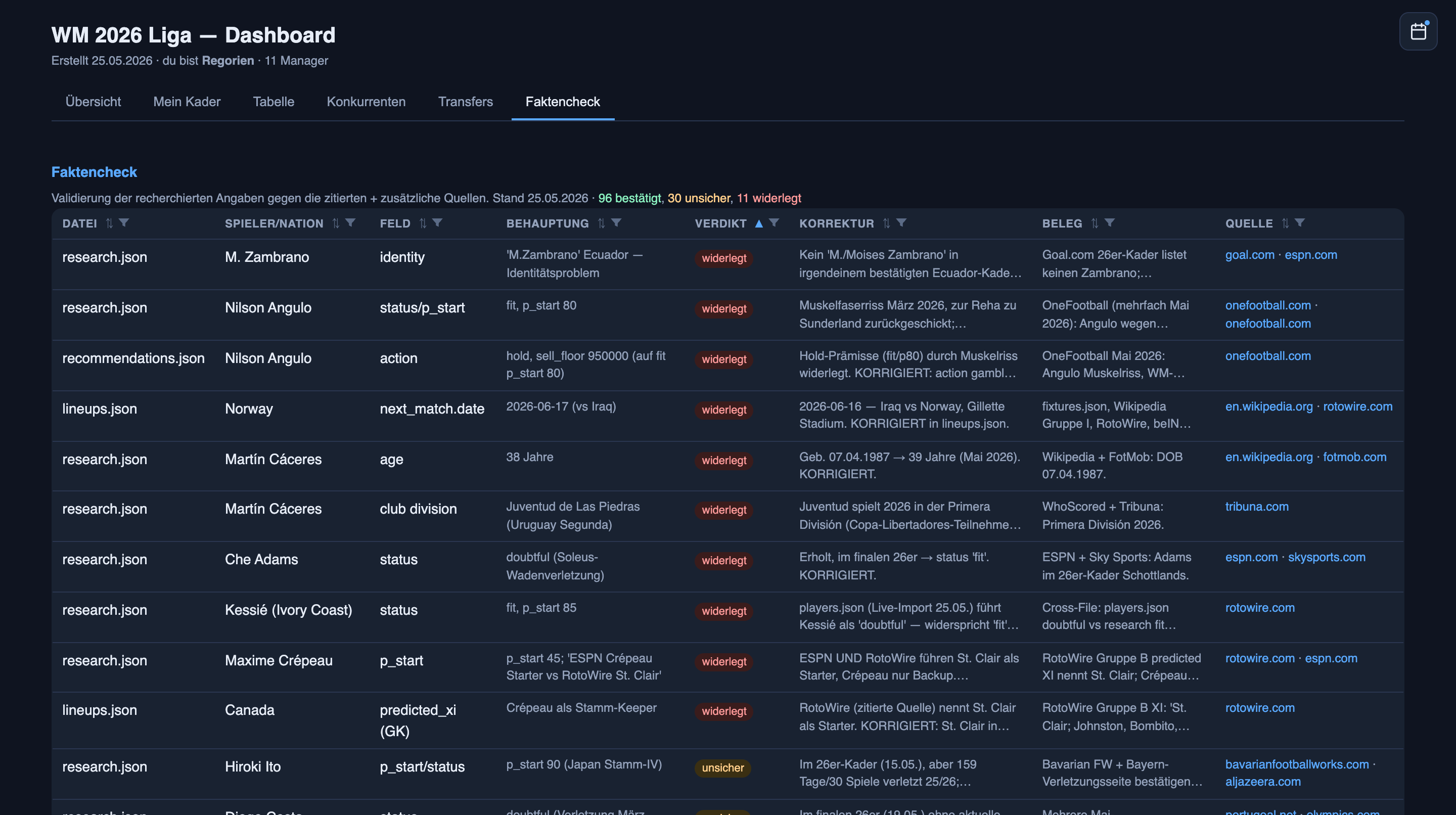
There’s a whole tab for it — a Faktencheck — and a separate agent that takes every football claim the system made and tries to verify it against the cited sources plus fresh ones. Each claim gets a verdict: confirmed, uncertain, or refuted. One recent run scored 96 confirmed, 30 uncertain, 11 refuted — 137 claims audited in a single pass, laid out in a table with the claim, the verdict, any correction, and the evidence:
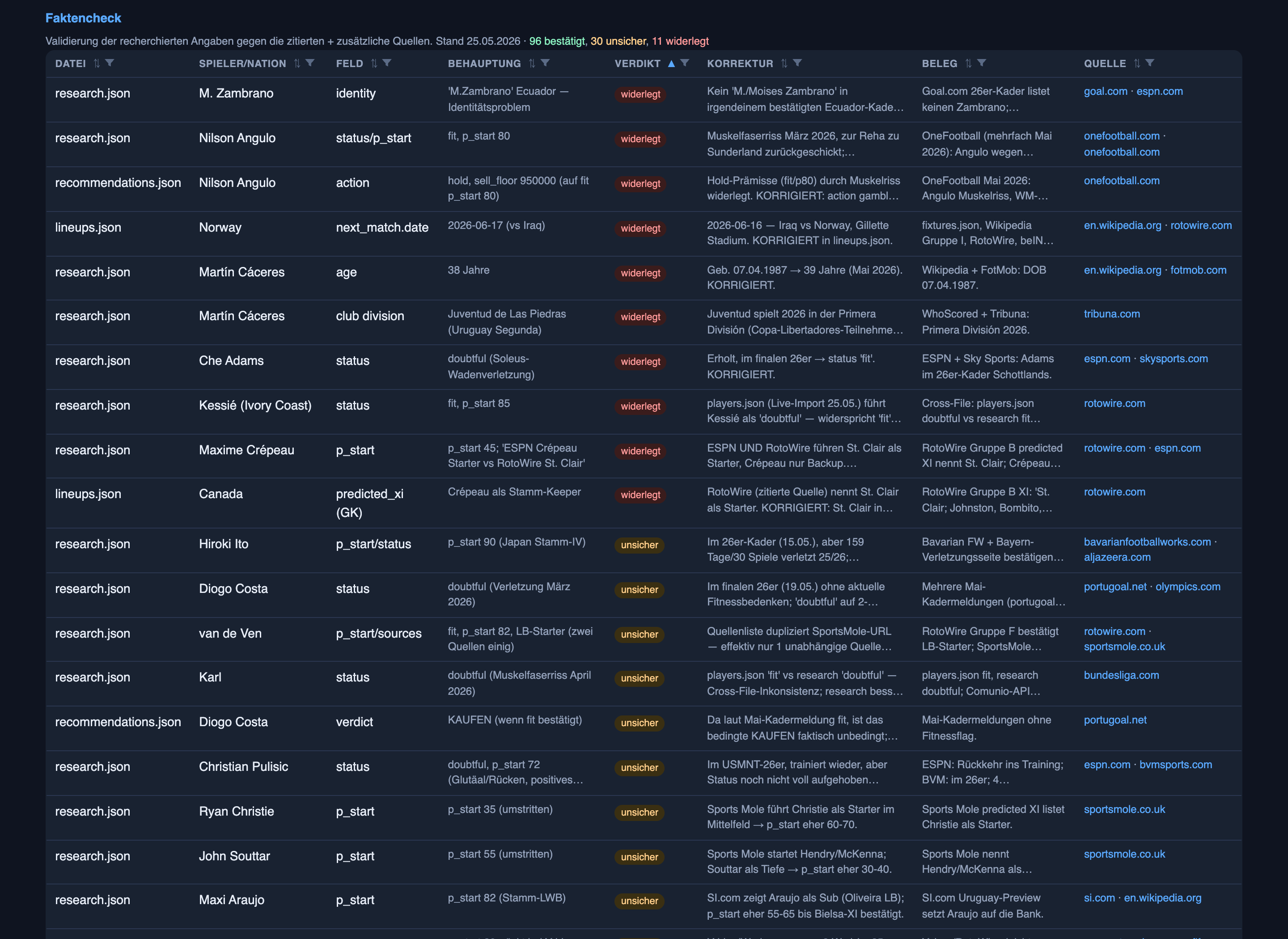
This morning’s run has all three verdicts on one page, and each is a small story. The Morocco call (Ez Abde out with a knee injury, misses the group stage) came back confirmed: the Moroccan federation plus three independent outlets agree. A research file had England’s World Cup opener as Ghana on 12 June; the fact-checker refuted it — England open against Croatia on the 17th, Ghana is the third group game — and corrected the file with the fixture list cited. And the Messi upgrade from section 2 came back uncertain: “fit” is slightly too optimistic, RotoWire still lists him as a game-time decision, and Argentina’s coach has only promised to “avoid any risks” — which is not a starter guarantee. The researcher’s optimism and the auditor’s skepticism, side by side on the same page, before I’ve bet a cent on either. Here is that page, from a few hours ago:
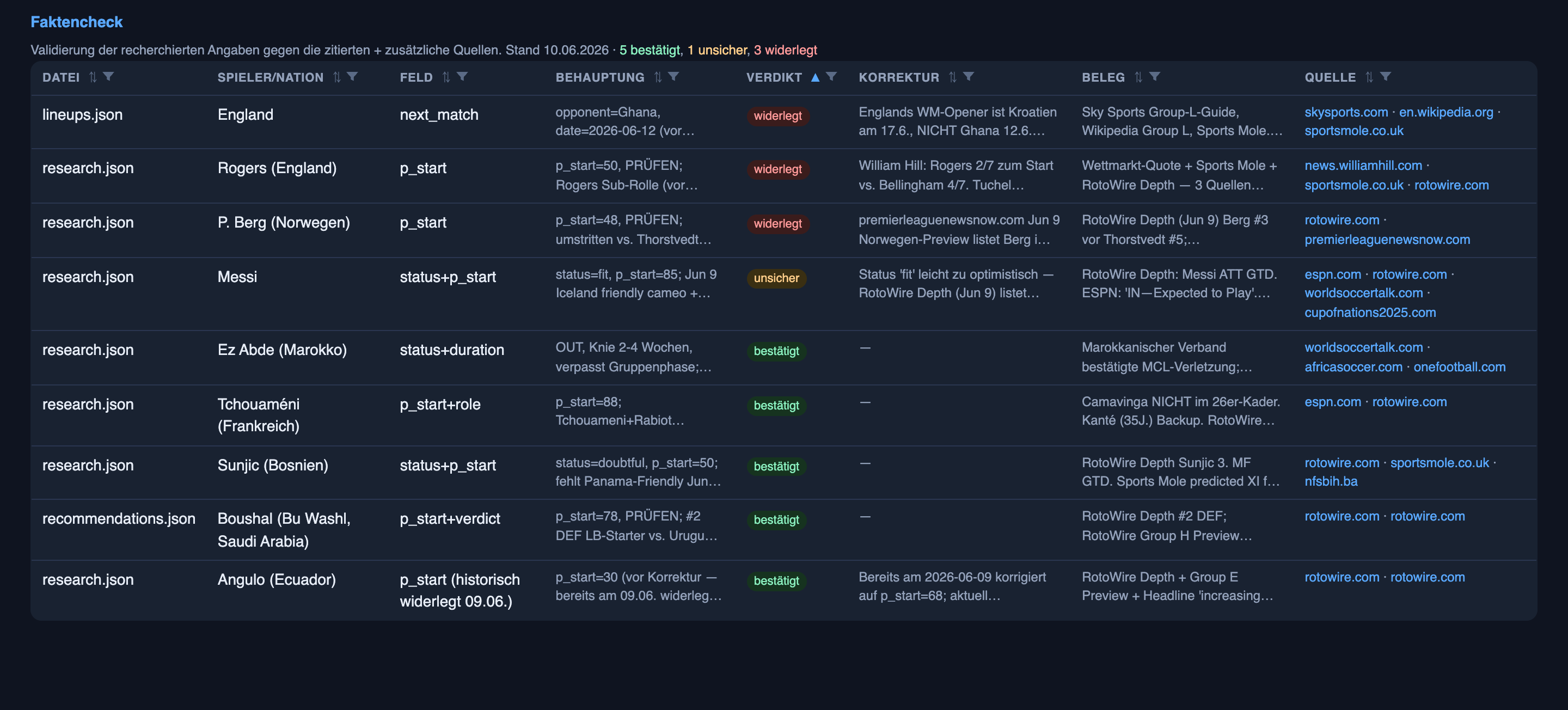
The rule it lives by is the strict one: a claim is only “confirmed” when an independent second source agrees. One source is a lead. Two is a fact.
Now, the honest caveat, because a fact-checker that only ever shows its wins is selling you something. Two sources agreeing isn’t bulletproof — sometimes both outlets are just rephrasing the same wire report, so you’ve “confirmed” one rumor twice. I lean on independent originators where I can, but correlated sources are a real failure mode, and it’s exactly the kind of thing the next section is meant to catch out in the open. The honest headline for anyone who’d run this for real isn’t “it cites sources” — it’s “how often does a confirmed claim turn out to be false,” and I don’t get to answer that until matches are played.
The fact-checker also exists for an unglamorous reason: early on, the agents got things wrong. One read a stale start-probability. One put a player in the wrong tournament group. One priced a transfer off the wrong market value. One referenced a player who matched nobody in any real squad — a ghost — and without the check I’d have found out by bidding on someone who didn’t exist. The fact-checker is the scar tissue from those mistakes: the layer that audits a decision before I act on it, the way a finance team keeps the person who books the invoice separate from the person who approves it.
7. The system is grading itself, live
The most recent thing I added — and the one I’m most curious to watch — is the part where the agents declare their predictions in advance, in public, and then score them against reality once the games are played.
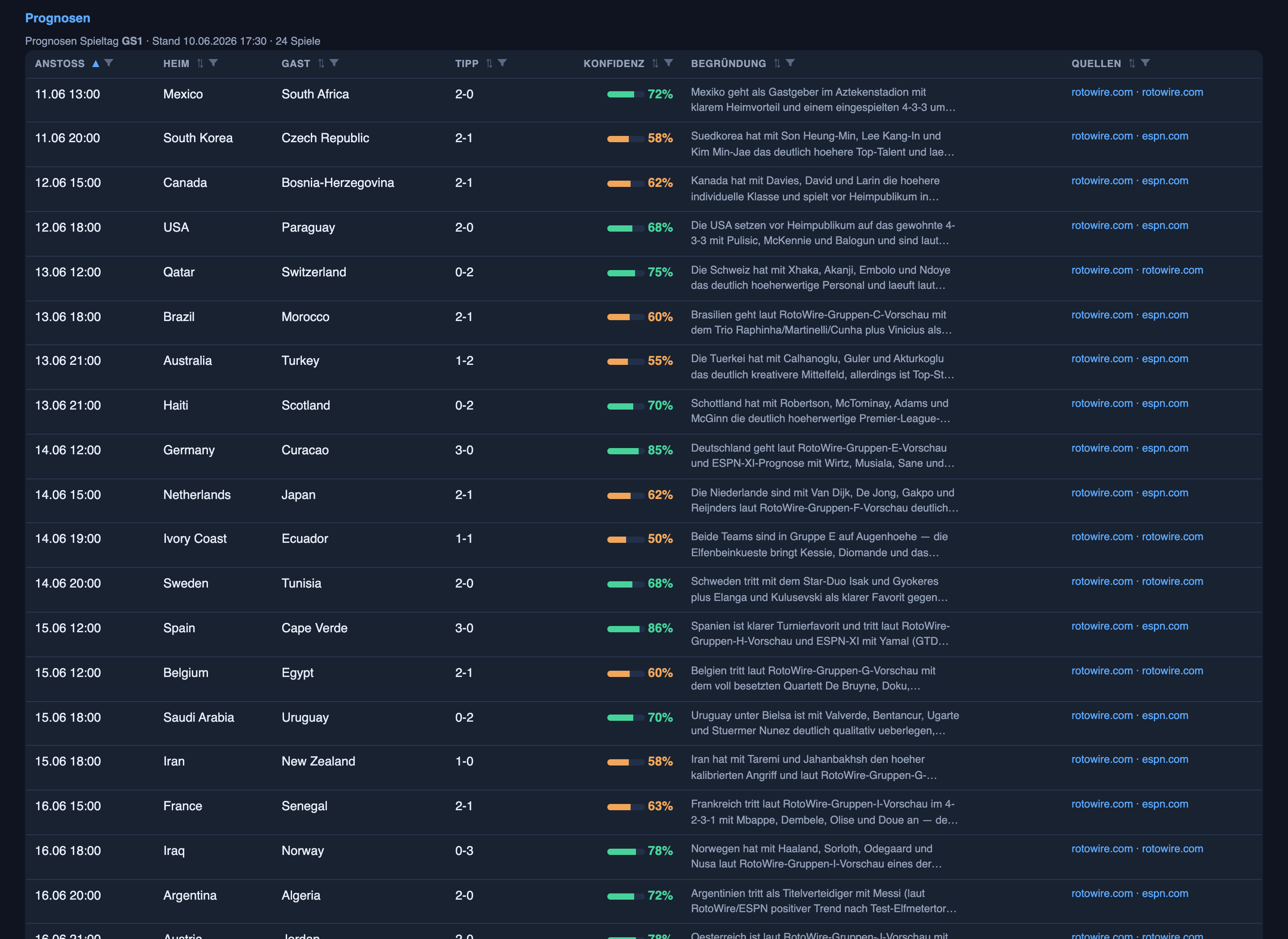
The Predictions tab tips every match of the current round — all 24 opening-round games right now, re-tipped as the news moves — each with a scoreline, a confidence percentage, the reasoning, and sources. Three calls from this morning’s board:
- Mexico vs South Africa — tomorrow’s opener — 2-0 at 72% confidence. “Mexico open at the Azteca with a clear home edge and a settled 4-3-3 around Jiménez and Alvarado; South Africa’s left-back is questionable with a hamstring, and they’ve shown offensive limits against top opposition all year. Plausible alternative: 1-0 — opening games are traditionally cagey.” Sources: rotowire.com.
- South Korea vs Czech Republic — 2-1 at 58%. Yesterday this exact row read 1-1 at 50% — an honest coin flip, no clear edge. Overnight the reasoning updated: Korea’s top-end talent (Son, Lee Kang-In, Kim Min-Jae) in a high-press 3-4-3, the Czechs leaning on one striker with his backup knocked. The tip moved to 2-1 because the information moved — in public, with yesterday’s version still sitting in the snapshot history. And where there’s genuinely still no edge, it says so: Ivory Coast vs Ecuador sits at 1-1, 50%, an admitted coin flip. That’s the discipline I want.
- Qatar vs Switzerland, 13 June — 0-2 at 75%. Switzerland’s settled 4-2-3-1 and far deeper squad; Qatar barely strengthened since 2022 and offensively harmless against organised European defences.
Then there’s a separate tab — Accuracy — that’s empty right now. Two sections live there: match-prediction accuracy (compares each tipped score to the actual result) and start-probability calibration (checks whether the “80% confident” claims actually come in at 80% in practice, bucketed by confidence level).
Both sections currently say: “No verified matchdays yet — values appear once the first matchday is complete.” That’s exactly what I want them to say. The infrastructure is there — public, dated, accountable. It starts filling in tomorrow night, and from then on you can check the system’s homework against reality without having to take my word for anything.
This is the part that matters for any business question. A system you can’t grade is a system you can’t trust. Most “AI dashboards” you’ll be shown in 2026 will quietly never get marked against the outcomes they predicted. This one has the marking page built in, with the columns named, before the first ball is even kicked.
8. How it’s built
For the engineers and the curious, here’s the shape of it, plainly.
First, the thing I keep insisting on, stated once and for real. A normal piece of software fetches data on a schedule and runs the rules you wrote in advance; change the question and you change the code. This doesn’t work like that. Each morning the agents decide what to look up, read it, reason about it, and can reach a conclusion I never pre-programmed — they change their mind when the news changes. The data is fetched daily and the analysis is computed on demand, by AI, not replayed from a static script. That’s the difference between automating a report and hiring an analyst who happens to be made of tokens.
It’s a multi-agent system. The simple version: instead of one big AI doing everything in sequence, I run a team of small specialists at the same time, each with one job. An “agent” here is just a small AI worker with one task and one checklist — like handing one analyst per region the same brief and letting them all work at once.
The daily pipeline is a clean line: log in → import the league → update the ledger → research → recommend → tip the matches → fact-check → render the dashboard.
The research is the nice part. I spawn one researcher agent per nation, all in parallel. Spain’s, Sweden’s and England’s researchers work at the same time, each returning a predicted starting eleven, per-player injury and form notes, start-probabilities, match score tips with confidence, and overpay-aware buy verdicts — as strict structured data, not prose. Then I spawn a fact-checker agent per nation, also in parallel, and crucially it’s independent and read-only — it can’t change anything, it can only return findings. The researcher proposes; the fact-checker disposes. Separating those two roles is the whole trick: the thing that makes a claim can’t also be the thing that approves it.
The plumbing that doesn’t need judgment — money tracking, standings, the valuation arithmetic, the accuracy scoring — lives in plain code with no AI in it at all. That’s deliberate, and it’s the part most people get backwards: use the expensive tool only where it earns its keep. The cheap, mechanical checks — does this price look sane, does this verdict match its own probability, does this player ID actually exist, does tipped 2-0 equal actual 2-0 — run in plain Python. The costly AI calls are reserved for the load-bearing judgment: reading the open web to verify the handful of claims a decision actually rests on. I cap it at two or three web fetches per nation and cache the anchor sources. Knowing which of your problems are hard reasoning and which are just arithmetic is most of what separates an AI demo from an AI system you can afford to run forever — and most “AI” systems I see in the wild get it exactly backwards and wonder why the bill is terrifying.
A word on cost, since it’s the first thing I’d ask. With the arithmetic kept out of the model and fetches capped, a full daily run lands in the cents — small single-digit dollars across all nations on a busy day, not the eye-watering bill people brace for when they hear “multi-agent.” The reason it’s cheap is the discipline, not luck: the model only ever does the part a model is uniquely good at.
Login is a real browser session driven by Playwright against comunio.com. Credentials come out of a password vault at runtime via a service token — never printed, never logged, never sitting in the code — and the session gets reused each run. For a hobby league that’s plenty. For a company it’s where the real conversation starts, not ends: where the data lives, who’s allowed to override a recommendation, whether an auditor would accept the trail, and the genuinely thorny bit — that scraping a fantasy site you have an account on is trivial, while monitoring competitors and pulling third-party data at a regulated firm is a terms-of-service and access minefield you design around from day one. I mention it not to wave it away but because pretending it isn’t there is how these projects die in legal review.
Did it work? Honest answer: ask me in a month — but the page is open.
The tournament kicks off tomorrow, 11 June 2026. As I write this, not a ball has been kicked. So I’m not going to tell you my agents are winning, because nobody’s won anything yet. The Messi arc and the Rogers correction above aren’t proven calls — they’re the system changing its mind as the news breaks, which is the behavior I wanted. But the scoreboard is still blank.
What I can show you is the system being honest under pressure, before kickoff, where it’s already checkable:
The Angulo arc. On 22 May it held him despite an injury flag — start-probability 50, value 0.49M — against the instinct to panic-sell. On 25 May a source claimed he was “fit, p80”; the fact-checker refuted it and corrected to p45. Then on 7 June: confirmed fit, p72, value up to 1.43M, squad place official. The value walked 0.49 → 0.52 → 1.43M while everyone else flinched. “Don’t panic-sell, hold to the squad lock” was the call, and it held. The three snapshots below are the system’s own dated records of that arc — I can time-travel to them anytime with the date-picker:
The Foden trap. On 22 May: AVOID. “Not in England’s 2026 squad. Worthless without the World Cup. The most expensive trap on the market — don’t bid.” Plainly correct, and a rival overpaid for him by +63% anyway. The warning was right there in the dashboard, with its sources — it’s still there in the 22 May snapshot. Somebody just didn’t read it.
And the table at the top of this article — Worldcup Allstars down 20.6%, me up 17.3% — is the system’s bookkeeping, before a single match has been played, on a gap of almost 21M that emerged purely from how each of us behaved in the market.
So that’s the honest state of things. The agents are disciplined, they cite their sources, they audit themselves, they’re already grading themselves on a public page that starts scoring tomorrow night. Whether they actually win the league is a question only June and July can answer.
Which is exactly why I’m turning this into a series. Two follow-ups are coming, both scored against reality after the fact, no grading on a curve:
- How accurate were the predictions? The system already has the page for it — empty as I write this, filling in from tomorrow onwards. I’ll write it up properly after the group stage, with the raw match-prediction accuracy and the start-probability calibration curves.
- How accurate was the information it gathered? A separate, and arguably more important, question — not “did the bet pay off” but “was the system’s picture of the world correct in the first place?” That’s where the false-confirm rate and the correlated-source problem get their public reckoning.
That second one is the question I’d ask before trusting any decision system, fantasy or otherwise. A system that wins by luck and one that wins because it saw clearly look identical on the scoreboard. The follow-ups are me trying to tell them apart, in public, where you can check my work.
A note before I let you go: the shape under the hood here — autonomous agents fetching fresh, citing every claim, auditing themselves, and grading their own predictions against reality — isn’t football-specific. The same pattern works against any moving target: procurement data, competitor pricing, supplier risk, the markets you actually live in. A football league is just where I chose to prove it in public, where the scoring is honest and the stakes are low. If the shape of it fits something you live with at work — and you’d want to see what a prototype looks like pointed at your domain — that door is open. Otherwise the smarter move is to watch the accuracy pages first: if a system can’t grade its own predictions against reality, none of the rest of this matters.
Now I get to find out if the agents were right. The scoring starts when the whistle does.